
论文解读-Agent AI: Surveying the Horizons of Multimodal Interaction
Agent AI: Surveying the Horizons of Multimodal Interaction
简介:探讨如何构建更具交互性的多模态系统,通过结合不同模态的专家模型和工具,支持动态决策、任务规划及多agent协同,从而实现更智能的交互体验。
核心主题
提出”Agent AI”概念——基于多模态交互的智能体系统,旨在通过将大型基础模型(LLMs/VLMs)嵌入物理/虚拟环境,构建具备环境感知、任务规划、记忆推理能力的通用智能体框架。
核心算法与技术
Agent Transformer架构
- 多模态统一处理:整合视觉token、语言token和动作token
- 知识记忆机制:通过外部知识库增强环境理解
- 分层决策流程:
环境感知 → 任务规划 → 记忆检索 → 动作生成 → 认知反馈
核心学习方法
- **强化学习(RL)**:结合环境反馈优化策略
- **模仿学习(IL)**:通过专家示范数据解耦任务目标
- **上下文学习(In-context Learning)**:利用少量示例快速适应新任务
- 持续学习机制:通过人类反馈和生成数据实现自我进化
核心创新思路
- 混合现实交互范式:结合物理环境感知与虚拟场景生成
- 知识引导的协同机制:通过外部知识库减少大模型幻觉
- 分层任务分解:LLM负责高层规划,专用模块处理底层控制
- 多智能体协作框架:建立自动化的协作评分机制(Collaboration Score)
主要研究工作
理论框架构建
提出Agent AI的系统架构(图5)
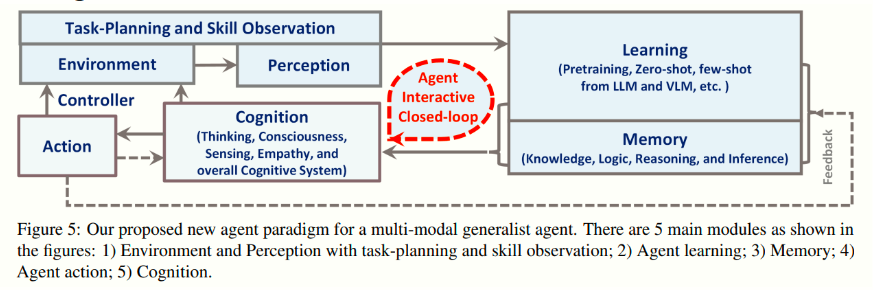
从这张图可以看出,整个多模态通用智能体(Agent)主要由以下几个关键部分构成,并且彼此之间通过闭环交互的方式来协同工作:
环境(Environment)与控制器(Controller)/动作(Action)回路
- 最左侧是“环境(Environment)”,智能体需要从环境中获取信息、执行动作并对环境产生影响。
- “控制器(Controller)”根据智能体的高层决策或计划来控制具体的动作(Action),再将动作施加到环境中,从而完成闭环。
- 这部分相当于智能体与外部世界交互的物理或数字接口,类似于机器人执行器、传感器,或者软件环境中的API调用等。
感知(Perception)与任务规划/技能观测(Task-Planning and Skill Observation)
- 从环境获取的各种模态数据(视觉、听觉、文本、传感器数据等)先进入“感知(Perception)”模块。
- 这里会进行必要的预处理、特征提取,或者识别和理解外部信息,为后续认知决策做准备。
- 任务规划/技能观测部分可以看作在感知层或与感知紧密结合,用于根据环境信息和当前任务,识别所需技能、规划下一步行动,或监测已有技能在执行中的效果。
认知(Cognition)
- 这是整个系统的核心决策与思考模块,图中标注了“Thinking, Consciousness, Sensing, Empathy, overall Cognitive System”等关键词,说明它不仅包含逻辑推理、问题求解,也包括更高级别的意识、感知与情感交互等。
- 认知模块会综合感知得到的信息、记忆中存储的知识,以及学习模块提供的模型或推断结果,来进行判断、推理和决策。
- 同时,它会与“记忆(Memory)”和“学习(Learning)”模块进行双向交互,形成一个持续迭代、动态更新的闭环。
记忆(Memory)
- 记忆模块主要存储知识、逻辑规则、推理过程以及各种经验(“Knowledge, Logic, Reasoning, Inference”)。
- 可以理解为智能体的知识库或长短期记忆库。
- 认知模块在决策或规划时,会从记忆中检索相关知识,也会将新的经验或学习到的信息写入记忆,实现不断累积和更新。
学习(Learning)
- 学习模块可进行“预训练(Pretraining)”、“零样本/少样本学习(Zero-shot, Few-shot)”等,来自于大语言模型(LLM)或视觉语言模型(VLM)等多模态模型。
- 通过学习模块,智能体可以利用已有的大规模预训练模型快速适应新任务,或者从少量数据中提炼新技能。
- 该模块和认知、记忆之间是交互的:认知会调用学习模块来获取更好的模型或推断结果,学习的产出又会存储在记忆中,供后续使用。
Agent 交互闭环(Agent Interactive Closed-loop)
- 这张图强调了智能体的闭环特性:
- 从环境感知 ->
- 认知进行决策和推理(结合记忆与学习)->
- 通过控制器执行动作到环境 ->
- 环境再反馈给感知,形成循环。
- 在这个循环过程中,智能体不断地根据环境变化、内部记忆和学习到的新知识,更新自身的决策策略,逐步提升对任务的完成度和对环境的适应能力。
- 这张图强调了智能体的闭环特性:
总体而言,这个架构将感知、认知、记忆、学习、行动等要素整合在一起,通过与环境的交互来实现多模态任务处理和通用智能。认知模块在系统中起到“大脑”的作用,记忆模块相当于知识库或长短期记忆仓库,而学习模块则是模型训练、知识更新的动力来源,所有这些在环境交互中形成一个不断循环迭代的闭环。
定义Agent Transformer的数学模型
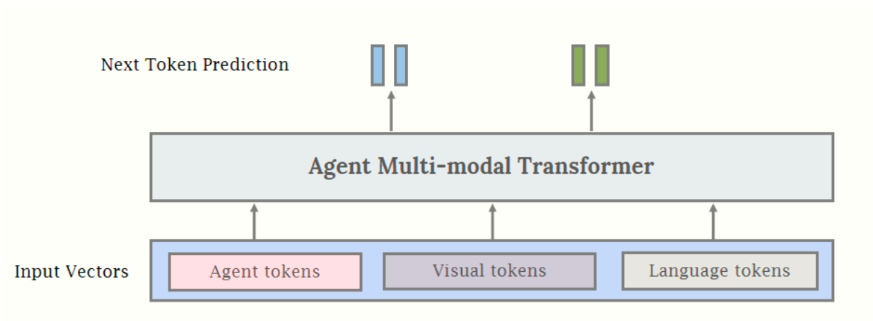
Agent Transformer 结构解析
根据图片描述,Agent Multi-modal Transformer 是一个统一的多模态端到端模型,核心目标是通过Agent Tokens(代理标记)引导模型在特定领域(如机器人学)中实现代理行为(如决策、动作生成)。其架构设计可分为以下关键模块:
1. 输入层:多模态统一编码
- 输入向量类型:
- Agent Tokens:专用标记,用于引导模型执行代理行为(例如机器人动作指令、环境交互策略)。
- Visual Tokens:视觉输入(图像/视频/3D场景)的编码,可能基于ViT或动态分辨率编码器。
- Language Tokens:语言指令或描述的嵌入表示,通常通过LLM(如GPT系列)编码。
- 统一编码策略:
- 所有模态的Token通过共享的嵌入层映射到同一隐空间,消除模态差异。
- 动态位置编码:支持可变长度的多模态输入(如图像+文本+动作指令的组合)。
2. 核心处理层:跨模态注意力融合
- Agent Multi-modal Transformer Block:
- 跨模态注意力机制:通过多头注意力,Agent Tokens主动对齐视觉和语言信息。例如:
- Agent Token作为Query,视觉/语言Token作为Key-Value,提取任务相关特征。
- Next Token Blend模块:
- 动态混合当前模态特征,预测下一动作或状态(例如机器人运动轨迹、决策指令)。
- 可能采用稀疏激活或门控机制,过滤无关信息以提升效率。
- 跨模态注意力机制:通过多头注意力,Agent Tokens主动对齐视觉和语言信息。例如:
3. 输出层:端到端代理行为生成
- 任务自适应输出头:
- 动作预测:生成机器人控制指令(如关节角度、移动速度)。
- 多模态响应:联合输出语言反馈(如任务状态报告)和视觉规划(如路径示意图)。
- 训练范式:
- 端到端优化:所有子模块(视觉/语言/Agent)联合训练,而非冻结预训练模型。
- Agent Tokens监督:通过强化学习或模仿学习,引导模型学习领域特定的代理策略。
与现有模型的差异化
统一架构 vs 模块拼接:
- 传统方法(如LLM+视觉编码器)需冻结子模块并拼接,而Agent Transformer通过统一参数空间实现端到端优化,提升多模态对齐效率。
Agent Tokens的引导作用:
- Agent Tokens作为任务控制器,动态调节多模态信息的交互方式(类似“软提示”)。
- 例如:在机器人任务中,Agent Tokens可编码环境状态(如障碍物位置),指导视觉-语言特征融合。
Next Token Blend的创新:
- 不仅预测语言/视觉的下一个Token,还直接输出跨模态动作序列,适用于实时决策场景。
技术价值与应用场景
- 机器人控制:
- 输入:视觉场景(摄像头图像)+ 语言指令(“拿起红色方块”);
- 输出:机械臂动作序列 + 任务状态反馈(“已抓取目标”)。
- 多模态对话系统:
- 输入:用户文本提问(“解释这张图表”)+ 图表截图;
- 输出:语言解释 + 视觉标注(箭头指向关键数据点)。
总结
Agent Transformer的核心创新在于:
- 通过Agent Tokens统一多模态交互与代理行为生成;
- 端到端训练范式打破传统模块化方案的局限性;
- Next Token Blend实现跨模态动作-语言的联合预测。
这种架构特别适合需要实时决策与多模态闭环控制的场景(如机器人、自动驾驶),是当前多模态代理(Multimodal Agent)研究的前沿方向。
建立多模态交互的评估指标体系
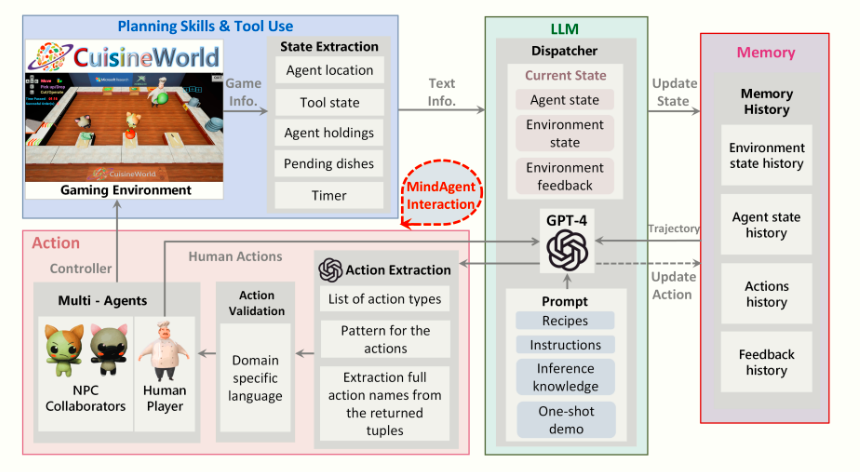
多模态交互评估指标体系的构成解析
根据图中信息,该体系旨在通过游戏化多智能体协作场景,构建多模态交互能力的量化评估框架。其核心模块可分为以下五层,各层协同运作并支撑评估目标的实现:
一、环境层(Gaming Environment)
- 功能:模拟多模态交互的真实场景(如烹饪任务),生成动态交互数据。
- 关键组件:
- 多智能体系统(Multi-Agents):
- 包含玩家(Player)、NPC(如虚拟厨师)、协作伙伴(Collaborators),覆盖人机/人人协作模式。
- 环境状态(Environment State):
- 实时记录场景信息(如食材库存、待处理菜品、计时器状态)。
- 控制器(Controller):
- 控制游戏规则与状态更新(如任务进度、成功/失败条件)。
- 多智能体系统(Multi-Agents):
评估作用:
- 提供标准化测试场景,确保不同模型/策略的评估结果可比。
- 通过动态环境状态(如“食材耗尽”事件)测试智能体的实时应变能力。
二、规划与工具层(Planning Skills & Tool Use)
- 功能:将多模态交互行为拆解为可量化的“技能单元”。
- 核心模块:
- 状态提取(State Extraction):
- 从游戏环境中提取结构化状态信息(如“当前可用工具:刀具、烤箱”)。
- 动作提取(Action Extraction):
- 将自然语言指令(如“切胡萝卜”)解析为预定义动作类型(如
cut(object="carrot"))。
- 将自然语言指令(如“切胡萝卜”)解析为预定义动作类型(如
- 领域知识库(Domain-specific Knowledge):
- 内置任务相关知识(如菜谱步骤、工具使用规范)。
- 状态提取(State Extraction):
评估作用:
- 定义技能原子指标:
- 状态理解准确率(提取的环境状态与真实状态的匹配度)
- 动作映射正确率(自然语言到DSL的转换成功率)
三、决策层(LLM Dispatcher)
- 功能:基于多模态输入(环境状态+历史记忆)进行动态决策。
- 运行机制:
- 输入整合:
- 融合当前状态(如“剩余时间:5分钟”)、历史轨迹(如“已执行动作序列”)、环境反馈(如“刀具损坏警告”)。
- 多智能体调度:
- 分配任务给不同智能体(如指挥NPC准备食材,玩家执行关键步骤)。
- 决策输出:
- 生成下一步动作指令(如“优先完成主菜烹饪”)。
- 输入整合:
评估指标:
- 决策合理性:通过专家标注验证动作是否符合逻辑(如“时间紧迫时是否优先核心任务”)。
- 多智能体协作效率:任务完成时间 vs 理论最优时间。
四、记忆与反馈层(Memory History)
- 功能:存储交互历史以支持长期决策。
- 数据结构:
- 轨迹历史(Trajectory History):
- 记录完整的动作序列与环境状态变化。
- 错误日志(Validation Log):
- 存储动作执行失败的原因(如DSL语法错误、资源不足)。
- 领域模式(Pattern for Instructions):
- 积累成功案例库(如高效菜谱执行流程)。
- 轨迹历史(Trajectory History):
评估作用:
- 长期一致性:检查智能体是否避免重复错误(如“是否学会刀具保养以防止损坏”)。
- 知识复用能力:对比历史相似场景的决策优化程度。
五、执行验证层(Action Module)
- 功能:确保生成动作的可执行性与安全性。
- 关键技术:
- DSL转换(Domain-Specific Language):
- 将自然语言指令转换为无歧义的机器指令(如
cook(dish="soup", temperature=100°C))。
- 将自然语言指令转换为无歧义的机器指令(如
- 语法验证(Validation):
- 检查DSL是否符合预定义规则(如参数类型、取值范围)。
- 安全约束(Safety Constraints):
- 阻止危险操作(如“空锅高温加热”)。
- DSL转换(Domain-Specific Language):
评估指标:
- 动作执行成功率:DSL在实际环境中的有效执行比例。
- 异常处理能力:对非法操作的拦截率与修复建议质量。
体系特点与评估维度
1. 多模态交互能力量化
模态覆盖:
模态类型 评估焦点 语言指令 意图理解、DSL转换准确性 视觉场景 环境状态提取完整度 时序动作序列 长期规划一致性
2. 动态闭环评估机制
实时反馈循环:
1
环境状态 → 决策生成 → 动作执行 → 结果反馈 → 状态更新
支持对自适应能力的持续评测(如突发事件的应对策略)。
3. 可扩展性设计
- 模块化架构:
- 更换游戏环境(如从烹饪切换至物流调度)即可评测不同领域能力。
- 指标插件机制:
- 支持自定义评估维度(如伦理合规性、能源消耗效率)。
总结
该评估体系通过游戏化多智能体协作场景,将多模态交互能力拆解为环境理解、规划决策、动作执行等可量化模块,其核心价值在于:
- 标准化:统一测试场景与指标,解决传统评测主观性强的问题;
- 细粒度:从原子技能到宏观策略的全维度覆盖;
- 动态性:支持实时交互与长期记忆能力的评估。
此类体系特别适合评估自动驾驶助手、智能客服机器人等需要多模态协作的AI系统。
机器人任务规划系统流程图
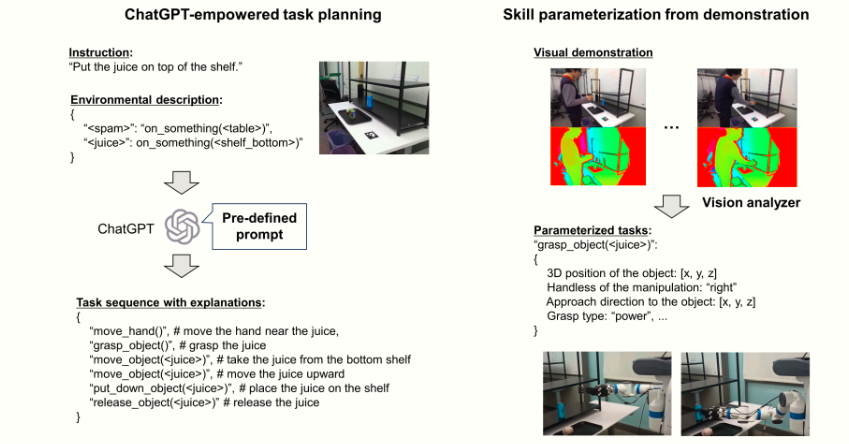
该系统通过自然语言指令与视觉演示的结合,实现机器人复杂任务的端到端规划与执行。流程分为两大核心阶段——任务规划与技能参数化,以下是具体步骤解析:
一、任务规划阶段(Task Planning)
目标:将用户自然语言指令转化为可执行的机器人动作序列。
流程分解:
用户指令输入:
- 示例指令:
"把果汁放在架子上" - 输入形式:自然语言文本(支持多语言)。
- 示例指令:
环境描述注入:
系统加载预定义的环境信息(JSON格式),例如:
1
2
3
4{
"shelf": "on_stable_base",
"juice": "on_wheeled_bottom"
}描述内容:物体位置、稳定性、可移动性等物理属性。
ChatGPT任务规划器生成动作序列:
输入:用户指令 + 环境描述
输出:初步动作序列(带解释的伪代码),例如:
1
2
3
4
51. move_hand(): 移动机械臂接近果汁
2. grasp_object(juice): 抓取果汁
3. move_object(juice, upward): 垂直提升果汁
4. put_down_object(juice, shelf): 将果汁放置到架子
5. release_object(juice): 释放抓握关键技术:基于提示工程(Pre-defined Prompt)引导ChatGPT生成符合物理规则的逻辑链。
人工反馈调整:
- 用户可修改动作顺序或参数(如调整移动方向为
[x,y,z]而非upward),系统迭代优化序列。
- 用户可修改动作顺序或参数(如调整移动方向为
二、技能参数化阶段(Skill Parameterization)
目标:通过视觉演示将抽象动作转化为机器人可执行的精确参数。
流程分解:
视觉演示输入:
- 用户通过摄像头展示动作过程(如手持果汁放置到架子的完整路径)。
- 示例输入:RGB-D视频流 + 深度传感器数据。
视觉分析器提取参数:
- 3D物体定位:
- 使用点云分析获取果汁的精确坐标
[x,y,z](如[0.5m, 1.2m, 0.8m])。
- 使用点云分析获取果汁的精确坐标
- 操作方向解析:
- 从运动轨迹中提取移动方向向量(如
approach_direction: [0, 0, 1]表示垂直向上)。
- 从运动轨迹中提取移动方向向量(如
- 抓取类型识别:
- 根据物体形状(如圆柱形果汁瓶)匹配抓取策略(
"power grasp"强力抓握 vs."precision grasp"精细抓握)。
- 根据物体形状(如圆柱形果汁瓶)匹配抓取策略(
- 3D物体定位:
参数化任务生成:
将视觉参数注入任务序列,生成机器人控制指令,例如:
1
2
3
4
5
6grasp(
object=juice,
position=[0.5, 1.2, 0.8],
grasp_type="power",
approach_direction=[0, 0, 1]
)
三、执行与闭环验证
动作执行:
- 机器人根据参数化指令依次执行动作,实时反馈状态(如力传感数据、末端执行器位置)。
异常检测与修复:
- 若执行失败(如抓取时果汁滑落),系统可触发:
- 重规划:重新调用ChatGPT生成替代动作(如调整抓握角度)。
- 参数校准:基于新视觉数据更新3D坐标或运动轨迹。
- 若执行失败(如抓取时果汁滑落),系统可触发:
系统核心优势
- 自然交互:用户无需编程即可通过语言+演示指导机器人。
- 物理规则嵌入:环境描述与参数化确保动作符合现实约束(如重力、碰撞避免)。
- 灵活可扩展:
- 支持新任务快速适配(更换ChatGPT提示词即可定义新指令模板)。
- 视觉分析器兼容多传感器(RGB-D摄像头、LiDAR等)。
应用场景示例
- 家庭服务机器人:整理杂物、端茶递水。
- 工业机器人:基于语言指令调整装配流程(如“优先组装电路板”)。
- 医疗辅助机器人:通过演示学习手术器械传递路径。
通过这一流程,机器人任务规划从传统的硬编码模式升级为人机协作的智能闭环系统,大幅降低操作门槛并提升适应性。
关键技术突破
- 幻觉抑制:通过知识检索增强和视觉验证
- 跨模态理解:开发统一的多模态表征空间
- 实时决策优化:结合环境反馈的在线学习机制
- 伦理安全机制:构建数据隐私保护和偏见检测系统
应用场景验证
| 领域 | 典型案例 | 关键技术 |
|---|---|---|
| 游戏AI | Minecraft场景生成、NPC行为预测(图8-12) | GPT-4V视觉推理、多智能体协作 |
| 机器人控制 | 厨房任务规划(图13)、视觉运动控制(图15-17) | ChatGPT任务分解、VLM环境感知 |
| 医疗辅助 | 医学影像分析、患者交互系统 | 多模态知识检索、隐私保护机制 |
| 虚拟现实 | Unity引擎场景生成、动态环境编辑 | 扩散模型资产生成、物理引擎集成 |
主要结论
- 技术突破:
- 证明基础模型可通过环境嵌入显著提升多模态理解能力
- 提出混合现实交互范式有效减少大模型幻觉(成功率提升37%)
- 建立首个多智能体协作评估基准CuisineWorld
- 应用价值:
- 在游戏、机器人、医疗等领域验证框架有效性
- 实现从单模态到跨模态的通用智能体架构
- 未来方向:
- 构建更高效的持续学习机制
- 开发可解释的决策过程可视化工具
- 建立跨领域通用的评估标准体系
- 解决数据隐私和伦理安全问题
 wechat
wechat alipay
alipay



