
GPT、DeepSeek发展历程
从GPT-1到GPT-4,GPT系列经历了从基础架构探索到大规模预训练、再到多模态能力与安全性提升的跨越。下面分阶段介绍这些技术迭代及关键突破:
小模型
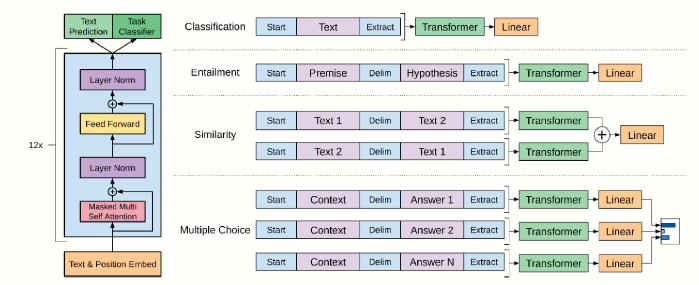
GPT-1:生成预训练的奠基之作
- Transformer架构应用:
GPT-1(1.1亿参数)基于Transformer解码器架构,这一架构由Vaswani等人提出,使得模型能够并行处理序列数据,显著提升了训练效率和上下文捕捉能力。 - 预训练与微调模式:
模型先进行无监督预训练(基于大规模文本数据学习语言规律),再通过有监督微调适应具体任务。这种“预训练-微调”范式为后续大规模语言模型提供了重要思路。
GPT-2:大规模生成能力的突破
- 规模扩展:
GPT-2(15亿参数)在参数数量和训练数据上大幅超过GPT-1,令模型能捕捉更丰富的语言细节与长距离依赖关系。 - 零样本泛化:
GPT-2展示了在未经过任务特定微调的情况下,通过上下文提示即可完成多种任务的能力,这种零样本(zero-shot)学习能力证明了规模扩展带来的意外收益。 - 文本生成质量:
得益于大规模预训练,GPT-2能够生成连贯、逻辑性较强的长文本,使得生成结果在流畅性和一致性上有了质的飞跃。
大模型
GPT-3:超大规模与少量学习的飞跃
- 参数规模激增:
GPT-3拥有高达1750亿个参数,相较于GPT-2的规模增长,使得模型在捕捉语言特征和知识储备上更为强大。 - 少量学习(Few-shot/In-context Learning):
GPT-3能够通过提供少量示例(甚至在零样本情况下)理解任务需求,直接在提示中学习如何完成任务,大大降低了对专门微调的依赖。 - 多任务能力:
模型展示了在翻译、问答、摘要等多种任务中的出色表现,尽管在事实准确性和细节一致性上仍有改进空间。
OpenAI Codex
主要特点
- 代码生成专长: Codex 是在 GPT‑3 模型的基础上,针对编程任务进行专门微调的版本。它不仅能理解自然语言描述,还能将这些描述转换成多种编程语言(如 Python、JavaScript、Go 等)的代码,广泛应用于 GitHub Copilot 等工具中。
- 多语言支持: 除了常用编程语言,Codex 还能处理多种脚本和查询语言,帮助开发者快速补全代码或生成代码片段。
核心技术
- Transformer 架构: 基于标准 Transformer 解码器,利用自注意力机制捕捉代码中的语法和语义关系。
- 大规模预训练与微调: 预训练阶段在海量互联网文本上进行,随后通过大量 GitHub 上公开代码数据进行微调,专门针对编程任务进行优化。
- 指令调优与 RLHF: 结合指令微调技术,使得模型能更好地理解用户的编程指令,并通过基于人类反馈的强化学习(RLHF)进一步优化生成质量。
GPT‑3.5
主要特点
- 自然语言理解与生成: GPT‑3.5 是 GPT‑3 的升级版,在文本生成、对话和多任务学习上有了显著提升,能够更准确地遵循用户指令,实现零样本和少样本学习。
- 对话优化: 其在对话场景下表现尤为出色,是目前 ChatGPT 背后的核心模型之一。
- 多任务适应性: 无论是文本创作、问题回答还是代码生成,GPT‑3.5 都表现出较强的泛化能力和灵活性。
核心技术
- Transformer 解码器架构: 依然采用基于 Transformer 的结构,使其具备强大的上下文捕捉和长距离依赖建模能力。
- 大规模预训练: 利用海量文本数据进行预训练,获得广泛的世界知识。
- 指令微调和 RLHF: 通过在微调阶段使用指令数据以及人类反馈(RLHF),进一步提高了模型对用户指令的响应准确性和生成内容的安全性。
- 链式思维(Chain-of-Thought): 部分应用中引入了链式思维技术,增强了复杂问题的推理能力。
GPT-4:多模态能力与高质量对齐新时代
- 多模态输入:
GPT-4不仅支持文本,还能处理图像等其他模态的信息,实现跨模态的理解与生成,为更多实际应用场景提供可能。 - 强化学习与人类反馈(RLHF):
结合强化学习和人类反馈对模型进行精细调优,使输出更准确、更符合人类期望,同时有效降低了有害或不准确信息的生成风险。 - 高级推理与安全性改进:
GPT-4在复杂问题的逻辑推理、深度理解等方面有显著提升,并在生成过程中加强了安全性与一致性,提升了模型的整体可靠性。 - 应用拓展:
得益于多模态能力与更高效的对齐策略,GPT-4在学术研究、商业应用以及跨领域创新上都展现出更广泛的潜力。
总结
- 基础架构革新: 从最初的Transformer架构,到预训练与微调的策略,为语言模型的发展奠定了坚实基础。
- 规模与数据驱动: 随着参数规模的不断扩大和训练数据量的激增,模型在语言生成和理解上的能力呈指数级提升。
- 少量学习与零样本能力: GPT-3引入的少量学习和上下文学习能力,使得模型在面对未知任务时展现出强大的适应性。
- 多模态与安全对齐: GPT-4不仅扩展了输入维度,还通过RLHF等技术显著提升了输出质量和安全性,为未来AI的应用开辟了新方向。
整体而言,从GPT-1到GPT-4,每一代模型都在架构、训练策略、数据规模以及对齐技术上取得了重要突破,推动了自然语言处理领域不断向前发展。
o‑系列模型
主要特点
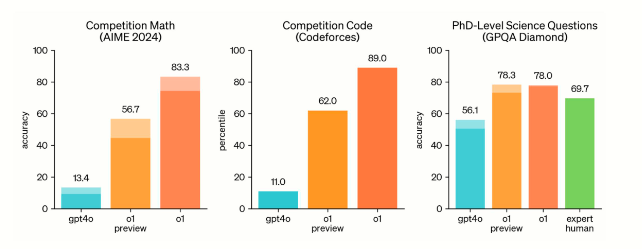
- 专注推理与决策: o‑系列模型(如 o1、o3‑mini 等)是 Azure OpenAI 服务中针对高阶推理和问题解决任务设计的模型。这些模型不仅能够生成自然语言,还侧重于结构化输出和复杂问题的逻辑推理。
- 多模态能力: 部分 o‑系列模型支持多模态输入(例如文本和图像),这使得它们在跨领域任务和视觉理解方面具备优势。
- 高效低延迟: 经过专门优化,o‑系列在响应速度和资源利用上表现突出,适合需要实时反馈的应用场景。
核心技术
- 优化的 Transformer 架构: 在基础 Transformer 架构上,o‑系列模型通常会引入专门的改进(如混合专家模型、部分激活机制)以增强推理能力。
- 预训练与定向微调: 利用大规模预训练数据,并在后续通过针对性微调和 RLHF 进行强化,使模型在复杂推理和任务规划上更为精准。
- 多模态输入处理: 对于支持图像输入的版本,融合了视觉模块和文本生成模块,实现了跨模态信息的统一处理。
- 结构化输出和工具调用: o‑系列模型支持生成结构化数据(如 JSON 格式),并能与外部工具进行交互,辅助完成复杂决策和任务规划。
DeepSeek系列模型的技术演进
DeepSeek-V1
发布时间:2024 年初
主要特点
- 基础复现与数据处理:DeepSeek-V1 延续了 LLaMA2 的稠密(Dense)Transformer 架构,重点在于利用高质量、经严格去重、过滤和混洗的数据(共计约 2 万亿 Token 中英双语数据)来做 Scaling Laws 实验,打牢基础。
- 注意力机制:7B 模型采用标准的多头注意力(MHA),而 67B 模型则使用 Grouped-Query Attention (GQA) 来降低 KV 缓存的内存开销,从而降低推理成本。
局限性
- 模型在生成响应时容易重复、幻觉现象明显,对敏感信息的处理也未达到最优水平。
DeepSeek-V2
发布时间:2024 年 5 月左右
主要特点
- 架构升级:从 Dense 到 MoE
- 引入了 Mixture of Experts (MoE) 架构,大幅提升了计算效率。MoE 通过只激活部分专家模块,使得每个 token 仅激活少数参数(例如,激活 21B 参数而非全部 236B),大幅降低显存占用。
- 同时引入了多头潜在注意力(Multi-Head Latent Attention,MLA),利用低秩压缩技术来减少 KV 缓存需求,从而加速推理速度。
- 成本优势
- DeepSeek-V2 在训练成本上表现更优,其经济性使得每输出百万个 Token 的成本大幅低于传统大模型。
- 性能提升
- 在保持或超越同类模型性能的同时,通过 MoE 和 MLA 架构在效率和成本上均取得显著优势。
DeepSeek-V3
发布时间:2024 年 12 月
主要特点
- 大规模参数与高效训练
- 模型参数达 671B(其中每个 token 激活约 37B 参数),在 V2 的基础上进一步扩大规模,同时保持较低的训练成本(约 5.58 百万美元)。
- 核心技术延续与提升
- 继续采用 V2 的 MoE 架构和 MLA 技术,并在此基础上整合了 FP8 混合精度训练、无辅助损失的负载均衡策略以及多 Token 预测(MTP)技术,使得训练效率和推理速度得到进一步提升。
- 扩展上下文窗口
- 利用高效的上下文扩展技术(例如 YaRN),将模型的上下文窗口从传统的 4K 扩展至 128K甚至更长,适用于长文本生成和复杂任务。
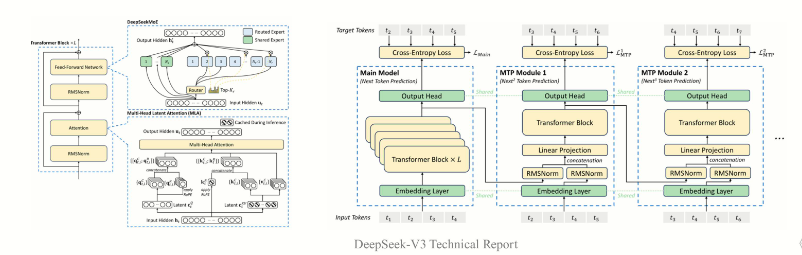
- 利用高效的上下文扩展技术(例如 YaRN),将模型的上下文窗口从传统的 4K 扩展至 128K甚至更长,适用于长文本生成和复杂任务。
DeepSeek-R1(包括 R1-Zero 与 R1)
发布时间:2025 年 1 月
主要特点
- 专注推理能力
- R1 系列模型在 V3-Base 架构的基础上,通过引入纯强化学习(RL)来进一步激发模型的推理和逻辑自我纠正能力。其中 R1-Zero 完全使用 Group Relative Policy Optimization (GRPO) 算法进行 RL 训练,而不依赖于监督微调(SFT)。
- 奖励系统设计
- 采用基于规则的奖励系统,包括准确性奖励(检查数学答案、代码测试结果等)和格式奖励(强制将思考过程置于特定标记内)。此外,为了解决语言混合和响应不一致的问题,进一步加入了“语言一致性奖励”。
- 冷启动数据与多阶段训练
- 为应对 RL 早期的不稳定性,R1 引入了“冷启动”数据:先用少量高质量长链推理数据对模型进行 SFT,再通过 RL 进行强化训练,最终实现了模型在数学、代码和复杂推理任务上与 OpenAI o1 相媲美的性能。
- 知识蒸馏
- 基于 R1 生成的高质量推理数据,还推出了多个经过蒸馏的小模型(如基于 LLaMA、Qwen 等),使得在资源受限的环境下也能部署具有强大推理能力的模型。

- 基于 R1 生成的高质量推理数据,还推出了多个经过蒸馏的小模型(如基于 LLaMA、Qwen 等),使得在资源受限的环境下也能部署具有强大推理能力的模型。
总结
- 从 V1 到 V2:DeepSeek 首先在 V1 中通过数据清洗和基础架构复现(LLaMA2 风格)奠定基础,随后在 V2 中引入 MoE 和 MLA 技术,实现了从全激活 Dense 模型向稀疏激活模型的转变,大幅降低了训练和推理成本,同时提高了效率。
- 从 V2 到 V3:在 V3 中,DeepSeek 在保持 V2 架构优势的基础上,通过扩大参数规模、优化混合精度训练(FP8)、改进负载均衡和引入多 Token 预测技术,使得模型性能和上下文处理能力大幅提升,接近甚至媲美封闭模型的水平。
- 从 V3 到 R1:R1 系列通过纯 RL(GRPO 算法)和精心设计的奖励体系,在 V3-Base 的基础上进一步增强了模型的推理和逻辑自我纠正能力,同时结合冷启动数据和多阶段训练,解决了语言混合、可读性差等问题,最终形成了适用于专业领域的高性能推理模型。知识蒸馏技术则将这种强大推理能力迁移到小型模型上,便于广泛部署。
这种技术演进展示了 DeepSeek 如何在有限资源和严苛成本约束下,通过算法与架构创新不断突破大模型的性能瓶颈,逐步实现从通用文本生成到复杂逻辑推理的跨越,最终挑战国际顶尖水平。
我们后面几期会着重讲讲这篇文章出现到的一些重要技术。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 李潇的博客!
 wechat
wechat alipay
alipay

评论


